Publications
Hierarchical Self-Supervised Adversarial Training for Robust Vision Models in Histopathology (Under Review)
Hashmat Shadab Malik, Shahina K. Kunhimon, Muzammal Naseer, Fahad Shahbaz Khan, Salman Khan
Adversarial attacks pose significant challenges for vision models in critical fields like healthcare, where reliability is essential. Although adversarial training has been well studied in natural images, its application to biomedical and microscopy data remains limited. Existing self-supervised adversarial training methods overlook the hierarchical structure of histopathology images, where patient-slide-patch relationships provide valuable discriminative signals. To address this, we propose Hierarchical Self-Supervised Adversarial Training (HSAT), which exploits these properties to craft adversarial examples using multi-level contrastive learning and integrate it into adversarial training for enhanced robustness. We evaluate HSAT on multiclass histopathology dataset OpenSRH and the results show that HSAT outperforms existing methods from both biomedical and natural image domains. HSAT enhances robustness, achieving an average gain of 54.31% in the white-box setting and reducing performance drops to 3-4% in the black-box setting, compared to 25-30% for the baseline. These results set a new benchmark for adversarial training in this domain, paving the way for more robust models.
Robust-LLaVA: On the Effectiveness of Large-Scale Robust Image Encoders for Multi-modal Large Language Models (Under Review)
Hashmat Shadab Malik, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar, Fahad Shahbaz Khan, Salman Khan
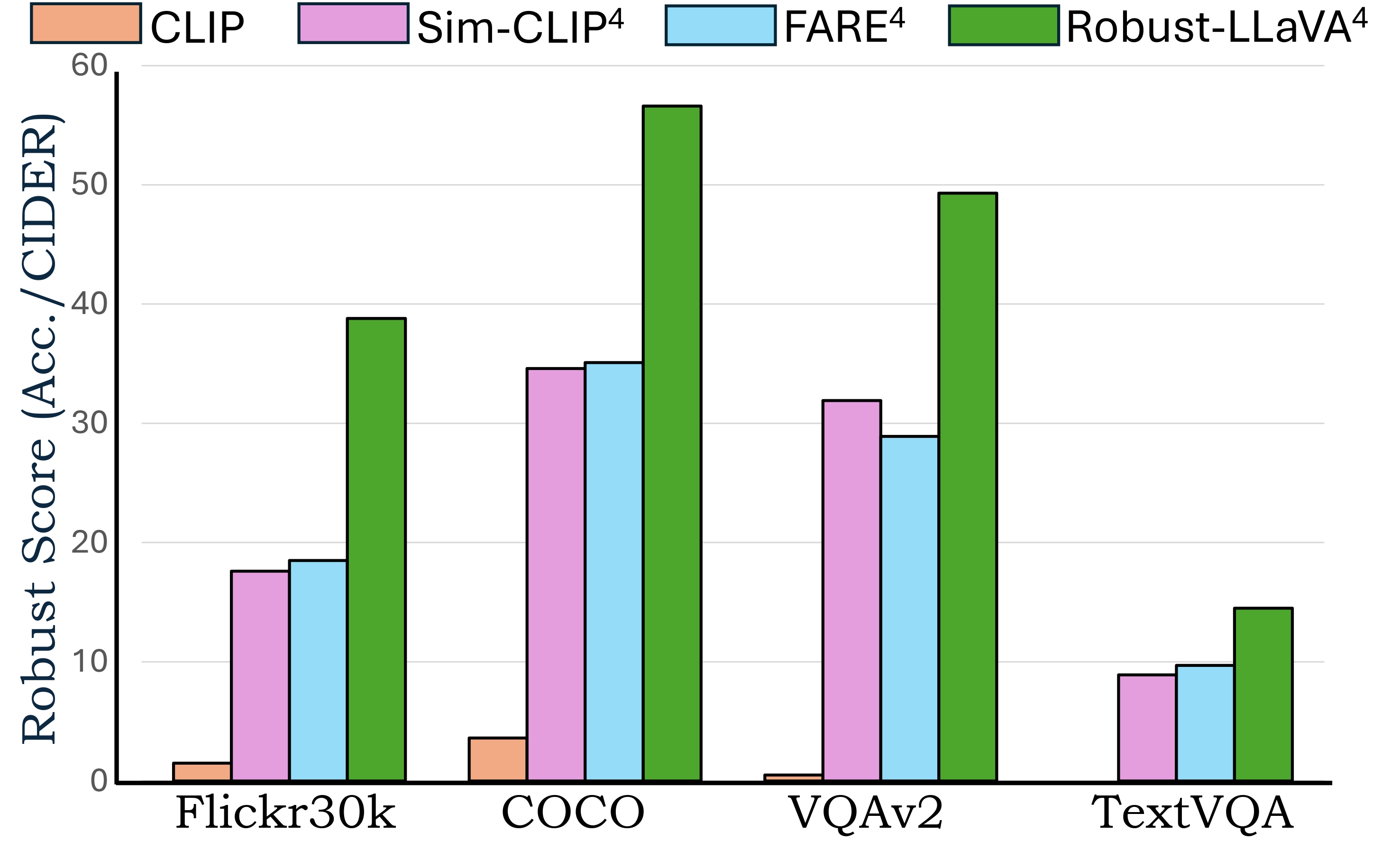
Multi-modal Large Language Models (MLLMs) excel in vision-language tasks but remain vulnerable to visual adversarial perturbations that can induce hallucinations, manipulate responses, or bypass safety mechanisms. Existing methods seek to mitigate these risks by applying constrained adversarial fine-tuning to CLIP vision encoders on ImageNet-scale data, ensuring their generalization ability is preserved. However, this limited adversarial training restricts robustness and broader generalization. In this work, we explore an alternative approach of leveraging existing vision classification models that have been adversarially pre-trained on large-scale data. Our analysis reveals two principal contributions: (1) the extensive scale and diversity of adversarial pre-training enables these models to demonstrate superior robustness against diverse adversarial threats, ranging from imperceptible perturbations to advanced jailbreaking attempts, without requiring additional adversarial training, and (2) end-to-end MLLM integration with these robust models facilitates enhanced adaptation of language components to robust visual features, outperforming existing plug-and-play methodologies on complex reasoning tasks. Through systematic evaluation across visual question-answering, image captioning, and jail-break attacks, we demonstrate that MLLMs trained with these robust models achieve superior adversarial robustness while maintaining favorable clean performance. Our framework achieves 2x and 1.5x average robustness gains in captioning and VQA tasks, respectively, and delivers over 10% improvement against jailbreak attacks.
Towards Evaluating the Robustness of Visual State Space Models (CVPRW)
Hashmat Shadab Malik, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar, Fahad Shahbaz Khan, Salman Khan
In this work, we present a comprehensive evaluation of VSSMs' robustness under various perturbation scenarios, including occlusions, image structure, common corruptions, and adversarial attacks, and compare their performance to well-established architectures such as transformers and Convolutional Neural Networks. Furthermore, we investigate the resilience of VSSMs to object-background compositional changes on sophisticated benchmarks designed to test model performance in complex visual scenes. We also assess their robustness on object detection and segmentation tasks using corrupted datasets that mimic real-world scenarios. To gain a deeper understanding of VSSMs' adversarial robustness, we conduct a frequency-based analysis of adversarial attacks, evaluating their performance against low-frequency and high-frequency perturbations. Our findings highlight the strengths and limitations of VSSMs in handling complex visual corruptions, offering valuable insights for future research.
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes [ACCV 2024 Oral]
Hashmat Shadab Malik*, Muhammad Huzaifa*, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan
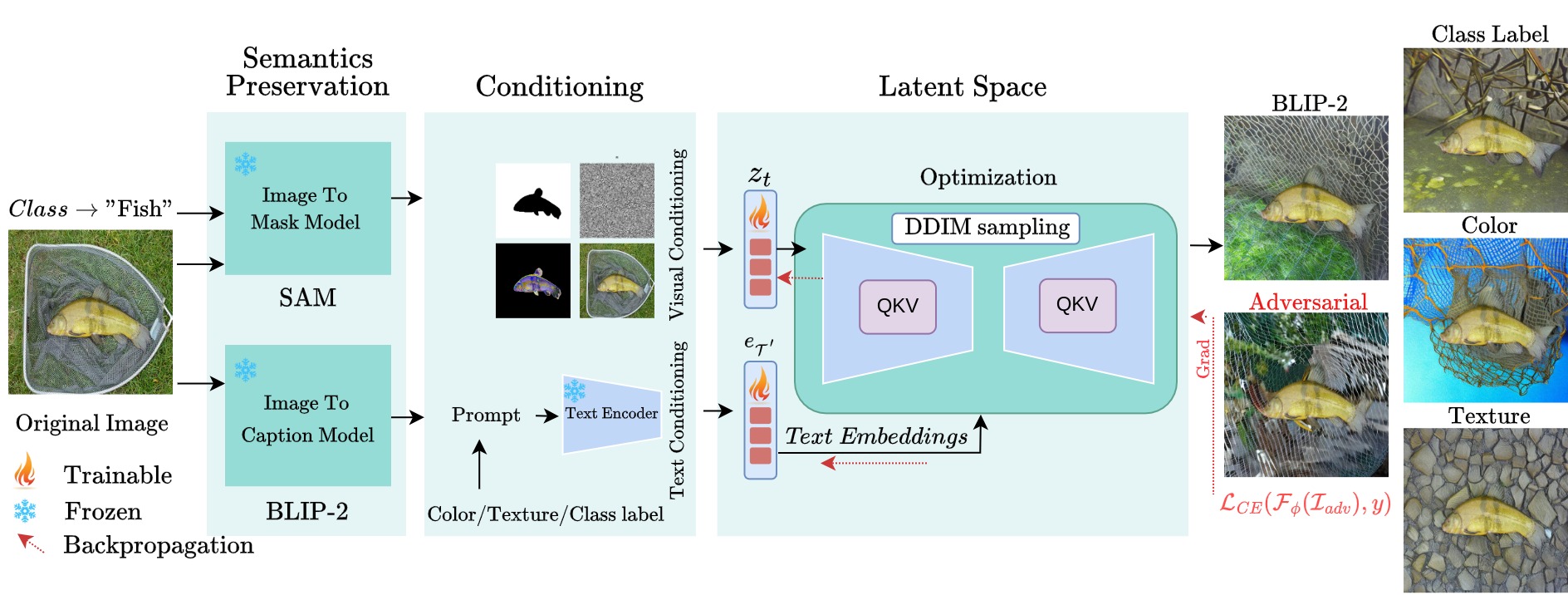
We propose ObjectCompose, which can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiments to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Evaluating Robustness of Volumetric Medical Segmentation Models [BMVC 2024]
Hashmat Shadab Malik, Numan Saeed, Asif Hanif, Muzammal Naseer, Mohammad Yaqub, Salman Khan, Fahad Shahbaz Khan
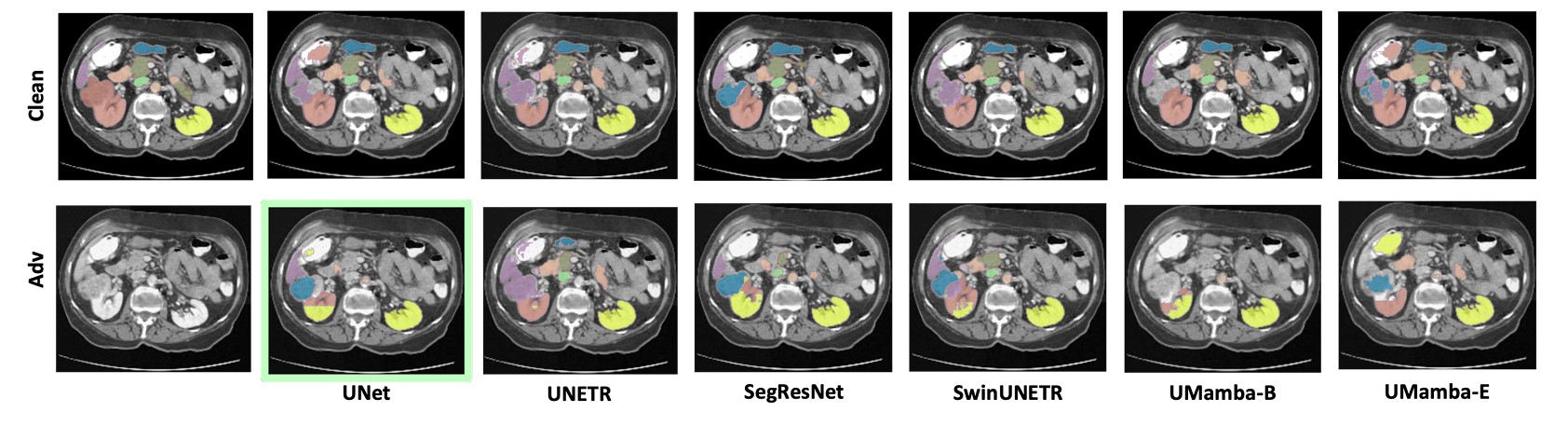
Our work aims to empirically examine the adversarial robustness across current volumetric medical segmentation architectures, encompassing Convolutional, Transformer, and Mamba-based models. We extend this investigation across four volumetric segmentation datasets, evaluating robustness under both white box and black box adversarial attacks. Overall, we observe that while both pixel and frequency-based attacks perform reasonably well under white box setting, the latter performs significantly better under transfer-based black box attacks. Across our experiments, we observe transformer-based models show higher robustness than convolution-based models with Mamba-based models being the most vulnerable. Additionally, we show that large-scale training of volumetric segmentation models improves the model's robustness against adversarial attacks.
Adversarial Pixel Restoration as a Pretext Task for Transferable Perturbations [BMVC 2022 Oral]
Hashmat Shadab Malik, Shahina K. Kunhimon, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan
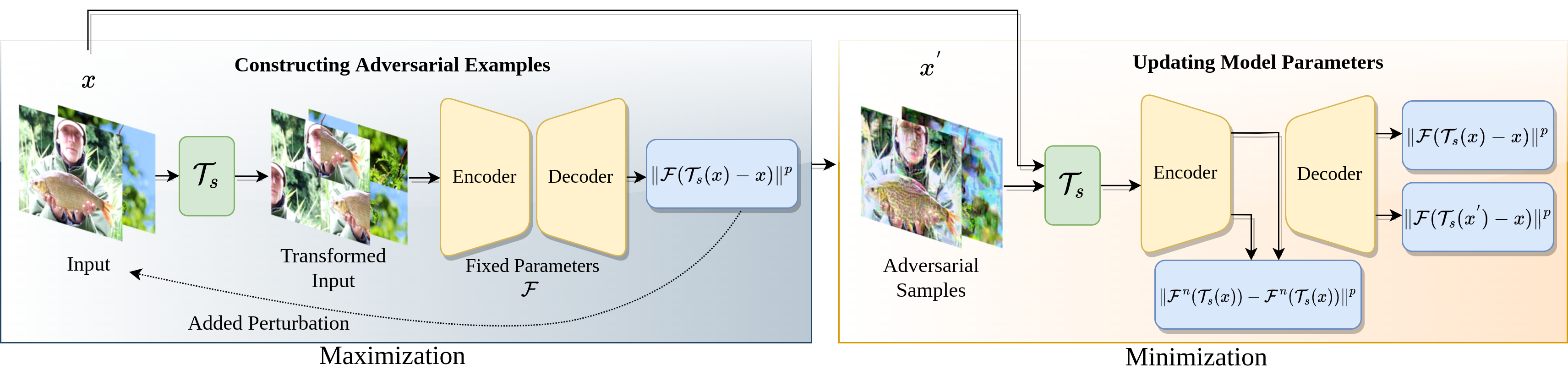
Transferable adversarial attacks optimize adversaries from a pretrained surrogate model and known label space to fool the unknown black-box models. Therefore, these attacks are restricted by the availability of an effective surrogate model. In this work, we relax this assumption and propose Adversarial Pixel Restoration as a self-supervised alternative to train an effective surrogate model from scratch under the condition of no labels and few data samples. Our training approach is based on a min-max scheme which reduces overfitting via an adversarial objective and thus optimizes for a more generalizable surrogate model. Our proposed attack is complimentary to the adversarial pixel restoration and is independent of any task specific objective as it can be launched in a self-supervised manner. We successfully demonstrate the adversarial transferability of our approach to Vision Transformers as well as Convolutional Neural Networks for the tasks of classification, object detection, and video segmentation. Our training approach improves the transferability of the baseline unsupervised training method by 16.4% on ImageNet val. set.